The Support-to-Engineering Gap: Why No Tool Owned This Until Now
 Jetson
JetsonJetson automatically finds bugs and feature requests hiding in your support inbox.
Try it freeThere’s a gap in every SaaS company’s toolchain that nobody talks about.
Support teams use Help Scout, Zendesk, or Intercom. They talk to customers all day. They know exactly which features are confusing, which bugs are recurring, and which parts of the product cause the most friction.
Engineering teams use GitHub or Linear. They build features, fix bugs, and ship releases. They need well-structured issues with reproduction steps, customer context, and — increasingly — enough detail for a coding agent to pick up and start working.
These two worlds are connected by… nothing. Or, more accurately, by a manual human process that everyone agrees is broken but nobody has fixed.
How it works today
In most SaaS companies, the flow from customer complaint to code fix looks something like this:
- A customer emails support about a bug
- A support agent resolves the customer’s immediate problem
- The support agent might mention it in a Slack channel
- A PM might see the Slack message
- The PM might create a ticket in the issue tracker
- The ticket might contain enough context for a developer to act on it
That’s a lot of “mights.” Each step is a potential failure point where customer intelligence gets lost.
And it gets worse at scale. When you have 50 conversations a day, a diligent support lead might manually flag the most critical bugs. When you have 500 conversations a day, nobody is reading them all. The support team is focused on resolution time, not product intelligence extraction.
The result is predictable: engineering teams work from incomplete information. They fix bugs they happened to hear about and miss bugs that customers report every week. Product teams prioritize features based on gut feeling and the loudest voices in Slack, not on what customers are actually asking for.
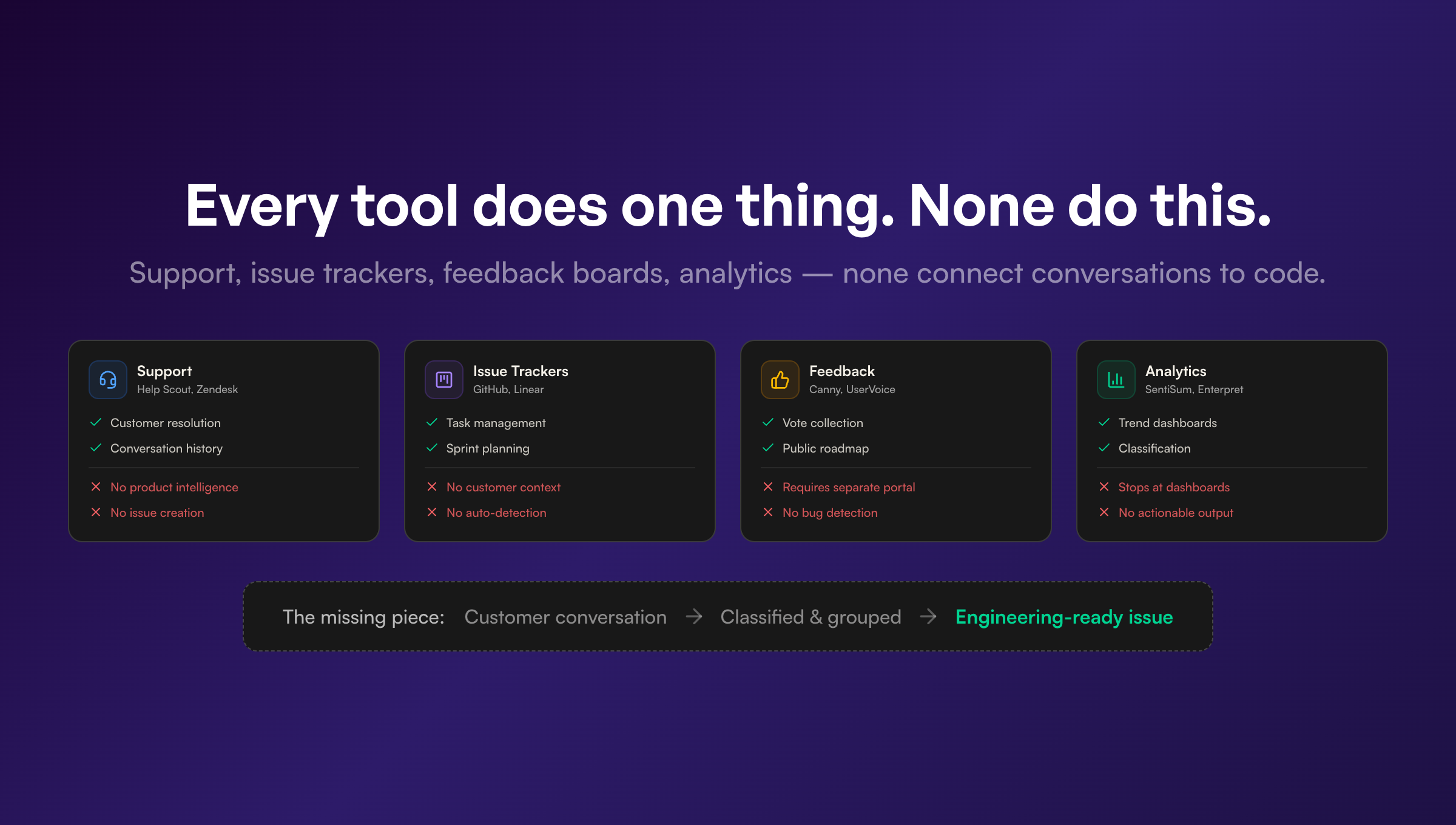
Why existing tools don’t solve it
You’d think someone would have built a tool for this by now. They haven’t — at least not one that works well. Here’s why.
Support platforms optimize for resolution. Help Scout, Zendesk, and Intercom are designed to help support agents respond to customers quickly. They have great conversation management, canned responses, and satisfaction scoring. But they don’t extract product intelligence from conversations. A resolved ticket is a closed ticket. The product insight inside it dies.
Issue trackers optimize for shipping. GitHub and Linear are designed to help engineering teams plan, track, and ship work. They’re great at managing backlogs, assigning tasks, and tracking progress. But they don’t know anything about customers. An issue in GitHub has a title and a description — it doesn’t know that 47 customers reported the same problem or what they specifically said.
Feedback tools optimize for collection. Canny, UserVoice, and Productboard are designed to collect and organize feature requests. They have voting boards, roadmaps, and prioritization frameworks. But they require customers to use a separate portal, which most never do. And they treat every piece of feedback as a feature request — they don’t distinguish between bugs, features, and noise.
Analytics tools optimize for aggregation. SentiSum, Enterpret, and Amplitude’s feedback features can classify support conversations and generate dashboards. But they stop at analytics. They tell you what’s happening — they don’t create actionable work items for engineering. A dashboard showing “authentication bugs up 23% this month” doesn’t help a developer fix anything.
Each category of tool solves a real problem. None of them solve the connection problem: taking a customer’s description of a bug in Help Scout, turning it into a well-structured issue in GitHub with reproduction steps and relevant code files, and doing it automatically.
What the gap actually costs
The cost of this gap is invisible because it shows up as opportunity cost, not as a line item.
Repeated bugs stay unfixed. The same bug gets reported by 20 customers over three months. Each time, the support agent resolves the individual ticket. Nobody realizes that 20 customers reported the same thing because the reports use different language — “can’t log in,” “login is broken,” “authentication error,” “password doesn’t work.” Without clustering these conversations, each one looks like a separate, low-priority issue.
Feature requests disappear. A customer describes exactly what they need and why they need it in a support conversation. The support agent helps them find a workaround and closes the ticket. The feature request — complete with business context and use case — vanishes. The customer doesn’t submit it to Canny. The support agent doesn’t have time to write it up for product. It’s gone.
Engineering works with bad inputs. When a bug does make it to the issue tracker, the ticket often says something like: “Multiple customers reported login issues.” That’s not actionable. The developer needs to know: which browser? which customers? what error? what were they doing? The original support conversation contains all of this. The issue tracker gets a watered-down summary.
PMs spend hours on manual triage. The average SaaS company spends 4-6 hours per week manually triaging support conversations for product insights. That’s a PM reading tickets, writing summaries, creating issues, and cross-referencing with existing tickets. It’s a part-time job that nobody hired for, and it’s the first thing that gets deprioritized when the PM gets busy.
Coding agents can’t help. This one is new but increasingly important. Tools like GitHub Copilot, Claude Code, and Cursor can fix bugs autonomously — if they have good inputs. A well-structured issue with reproduction steps, customer quotes, and relevant code files is exactly what these tools need. A vague one-liner ticket is useless. The support-to-engineering gap doesn’t just slow down human developers; it blocks AI ones entirely.
The gap is structural, not cultural
It’s tempting to think this is a process problem. “Just get support and product to communicate better.” But the gap persists even in companies with great internal communication.
The reason is structural: support platforms and issue trackers are designed for different audiences with different needs. A support conversation is optimized for the customer — it’s in their language, organized around their problem, embedded in the context of their relationship with you. An engineering issue is optimized for the developer — it needs technical detail, reproduction steps, code references, and a clear definition of “done.”
Translating between these two formats is skilled work. It requires understanding both the customer’s problem and the product’s architecture. Most companies rely on a PM to do this translation manually, which means it happens for maybe 10% of conversations. The other 90% stay trapped in the support platform.
What “solving” it actually looks like
The gap between support and engineering needs a tool that does three things:
Read support conversations automatically. Connect to Help Scout, Zendesk, or Intercom and process every conversation — not just the ones someone manually flags.
Classify and cluster intelligently. Distinguish bugs from feature requests from noise. Group the same issue reported 20 different ways into a single pattern. Rank by customer count so the biggest problems surface first.
Create engineering-ready work items. Generate issues in GitHub or Linear with customer quotes, reproduction context, and enough detail for a developer — or a coding agent — to start working immediately.
This isn’t AI for AI’s sake. It’s automating a translation process that every SaaS company does manually, badly, for a fraction of their support conversations.
The technology to do this well has only recently become available. LLMs can understand natural language well enough to classify conversations accurately, cluster similar issues despite different wording, and extract the specific details that developers need. Two years ago, this would have required a team of NLP engineers and months of model training. Today, it’s a product problem, not a research problem.
The support-to-engineering pipeline
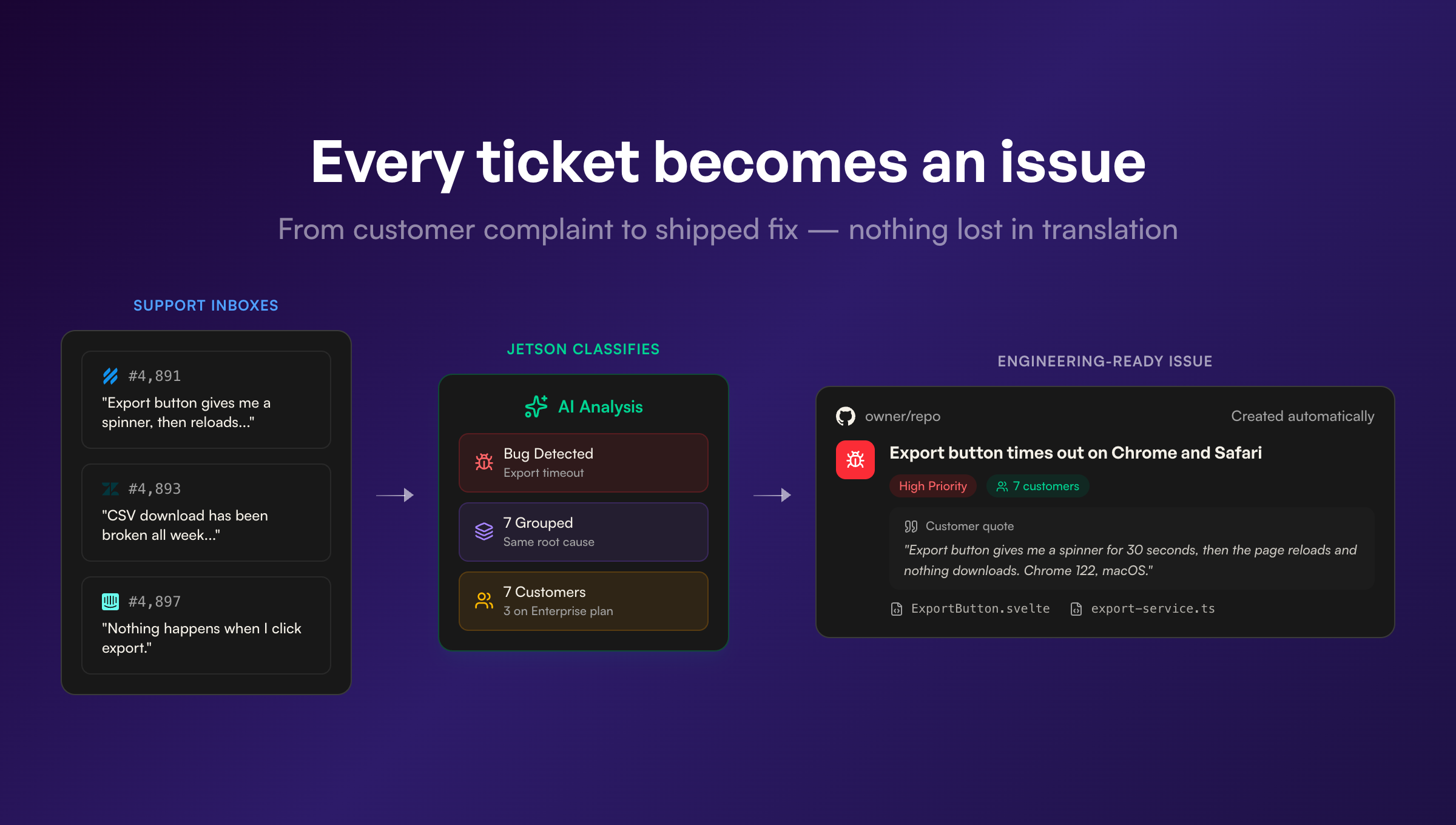
Here’s what the pipeline looks like when it works:
Customer emails support → “I’ve been trying to export my Q4 report for the last 20 minutes. The Export button gives me a spinner, then the page reloads.”
Classification → Bug report. Export feature. Affects Chrome and Safari. Multiple customers.
Clustering → Grouped with 6 other conversations about the same export timeout. 7 customers total, 3 on enterprise plans.
Work item → GitHub issue with: title, description synthesized from 7 customer conversations, direct quotes from customers, 7 affected customers listed, relevant code files suggested by AI, reproduction steps extracted from conversation context.
Resolution → Developer (or coding agent) picks up the issue, has everything they need, ships the fix. Customers stop emailing about it.
That’s the whole pipeline. Customer reports a problem at 2pm. Engineering sees a well-structured issue at 2:01pm. The fix ships by end of day. Support volume for that issue drops to zero.
No PM spent an hour writing a ticket. No Slack message got lost in the noise. No dashboard had to be interpreted. The signal went from customer to engineer with nothing lost in translation.
We built Jetson to close this gap. It connects to Help Scout, Zendesk, and Intercom, classifies every conversation, clusters related issues, and creates GitHub and Linear issues with full customer context. If you want to see what you’re missing, try the free audit — connect your support inbox and get a full analysis of your last 50 conversations in two minutes.